When I was a child, I was always fascinated by stories about ancient civilizations. I devoured books about Atlantis, or the story of Heinrich Schliemann’s discovery of Troy, stories about the Greek, the Romans, the Inca Empire, or Ancient Egypt. And I was alw… Read More
Today, the Trident Era Ends

When I was a child, I was always fascinated by stories about ancient civilizations. I devoured books about Atlantis, or the story of Heinrich Schliemann's discovery of Troy, stories about the Greek, the Romans, the Inca Empire, or Ancient Egypt. And I was always fascinated by the extent of their capabilities in the fields of astronomy, math, and medicine, their incredible achievements, like building those vast monuments, or their highly functional social systems. What's even more incredible is that most of this already happened way before Jesus Christ first set foot on our earth!
And yet, all these eras of highly developed civilizations one day came to an end. Some just died out quietly, some were outpaced by civilizations with better military capabilities. Most of the time when that happened, the capabilities of the defeated ones did not carry over to the now dominating group, thereby enriching their pool, but instead vanished. Which I always found unfortunate.
The Era of the Trident Engine #
Starting now, Microsoft will roll out their new Chromium-based Edge browser to their millions of Windows 10 users. And this will also mark the end of an era. The era of the Trident-Engine.
But hadn't the Trident era already ended when Edge appeared? Not really.
When Microsoft created the Edge browser in 2015, what they really did was to fork Trident into EdgeHTML and to strip out plenty of legacy code paths like ActiveX (Microsoft's version of Java Applets) or emulation of older IE rendering engines. Both browsers sharing the same genes gets apparent when you read posts like these on the Edge Blog or when you see bug reports that similarly affect IE 11 as well as Edge 17. Most of the initial Edge improvements came from Chakra, the JavaScript engine, whereas only a moderate few could be attributed to the rendering engine itself. Renaming the browser could be considered more of a marketing move, though, as the removal of legacy features already started earlier, when the browser was still called Internet Explorer.
Rebooting Internet Explorer under a new name didn't win back the hearts of the web developers. Up until today Microsoft remained busy playing catch up. Therefore, when we get excited about the web platform nowadays, it is not because of a new Edge release but because of Google unveiling new ideas or APIs during Google I/O or the Chrome Dev Summit. A lot of these innovations are driven by other teams at Google working on Google frameworks like Angular and AMP, or on Google products like Gmail, Search, Drive, Maps, Google Docs, Analytics or in recent times: Lighthouse. In fact, a lot of what defines HTML5 can be rooted back to Google looking for a way to improve the web platform to better accommodate its ideas around web apps. Remember Google Gears? Or later Google Chrome Frame?
Funnily that same kind of process also drove innovation in Internet Explorer in the old days. ActiveX capability was added to Internet Explorer 3.0, together with the <object> tag, to offer one more "compile target" for Microsoft's own Java competitor. It was certainly not the IE team that came up with this idea. Or take what we know today as "AJAX": the idea of lazily fetching content in the background via JavaScript was born in the Exchange / Outlook Web Access team, a product that could be seen as a precursor to Gmail. After pulling a few tricks inside Microsoft they got it (silently) shipped with Internet Explorer 5.0 in 1999. It wasn't until 6 years later that the term AJAX was coined and its concepts became widely known.
we pretty quickly struck a deal to ship the thing as part of the MSXML library. Which is the real explanation of where the name XMLHTTP comes from- the thing is mostly about HTTP and doesn't have any specific tie to XML other than that was the easiest excuse for shipping it so I needed to cram XML into the name (plus- XML was the hot technology at the time and it seemed like some good marketing for the component).
The same goes for document.designMode (apparently a wish coming from the Hotmail team) & contentEditable, the DOM the Drag-n-Drop API, iframes or Clipboard Access. Internet Explorer was also the first browser to have permission prompts:
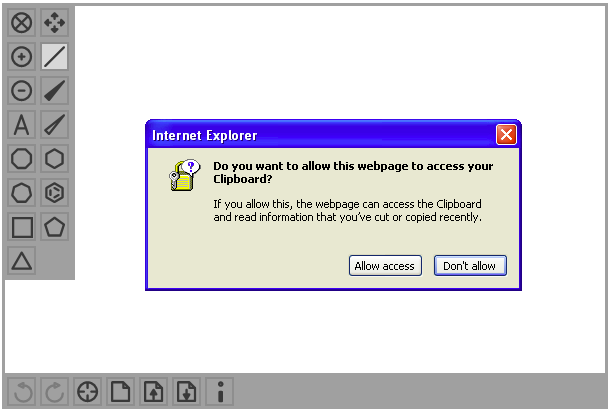
Back in the days, Microsoft was single-handedly pushing the web forward, with around 1.000(!) people working on Internet Explorer and with a 100 million dollar budget to burn per year, with almost no-one left to compete. This was massive!
[Scott] Isaac also invented the iframe HTML tag. It has been speculated that the tag name stands for the Isaacs Frame, although Scott has denied this.
The last time Internet Explorer introduced new features driven by other business units was in 2012. At that time Windows 8 introduced the Windows Store and corresponding Windows Store Apps. Those apps could be written once and could then be run on Windows, Xbox and Windows Phone. Since Microsoft was late to the app store game, they had to put the entry barrier for developing apps as low as possible, so they got the idea of allowing people to develop apps with web technologies. As a communication path to the underlying OS, they created a JavaScript library called "WinJS" and Internet Explorer 10 was meant to be the runtime environment for those apps.

But to be able to model the Windows UI with web technologies, Microsoft had to add plenty of new capabilities to IE: CSS Grid, CSS Flexbox, CSS Scroll Snap Points and the Pointer Events API for touch and stylus interactions (the latter one was required as Apple had filed a patent on the Touch API).
Microsoft even invented what later became Origin Trials, as documented in a podcast interview we did with Jacob Rossi from the Edge team in 2015.
Coming back to my introductory part on ancient civilizations and their achievements: For me, it feels like Internet Explorer already had many of the things that we came to reinvent later and that we now celebrate as innovations. Although our modern reinventions offer more features combined with better developer experience, I came to wonder why we, as a community, only picked up very few of them. The ones mentioned above were picked up - either because browsers were striving for compatibility with IE or because Microsoft was at the right place at the right time. But a lot more were not!
The Forgotten Parts #
MHTML #
The first one on the list is MHTML. MHTML or "MIME encapsulation of aggregate HTML documents" was meant as a packaging format. It shared a lot of concepts with how email clients append attachments to an email. MHTML would take an HTML file and inline all of its resources like CSS, JavaScript files or images via base64 into extra sections. So it was basically data URIs, but on steroids. You could also see MHTML as the precursor of Web Bundles. The format was supported from IE 5 onwards, as well as in Presto-based Opera. No other browser officially supported MHTML, but Chromium added the feature later behind a flag called chrome://flags/#save-page-as-mhtml. MHTML was proposed as an open standard to the IETF but somehow it never took off.
Fun fact: Did you know that Outlook Express used MHTML inside the .eml email message files, which it used to store emails together with their corresponding attachments on your disk?
Page Transition Filters #
Internet Explorer had page transition filters which you would define as HTTP header or in the form of a meta tag:
<meta http-equiv="Page-Enter"
content="RevealTrans(Duration=0.600, Transition=6)">As the name implies, such a filter would smoothly transition the user from page to page upon navigation, instead of having pages appear as abruptly as we are used to. There was an extensive list of transition filters you could choose from by referencing them via number:
- 0 - Box in
- 1 - Box out
- 2 - Circle in
- 3 - Circle out
- 4 - Wipe up
- 5 - Wipe down
- 6 - Wipe right
- 7 - Wipe left
- 8 - Vertical blinds
- 9 - Horizontal blinds
- 10 - Checkerboard across
- 11 - Checkerboard down
- 12 - Random dissolve
- 13 - Split vertical in
- 14 - Split vertical out
- 15 - Split horizontal in
- 16 - Split horizontal out
- 17 - Strips left down
- 18 - Strips left up
- 19 - Strips right down
- 20 - Strips right up
- 21 - Random bars horizontal
- 22 - Random bars vertical
- 23 - Any random pattern
In addition to Page-Enter you could specify additional transitions for Page-Exit, Site-Enter and Site-Exit. Those soft transitions between pages are something that we see reappearing in the form of Portals or the Page Transition API.
Object Transition Filters #
Similarly to how you could use filters to transition between pages, you could also transition between two states of the same DOM object. This is similar to Rich Harris' ramjet, only that it would not morph between two states, but instead blend over with a movie-like "cut".
What you could also do with those object transition filters is something similar to CSS Transitions or to an animated CSS crossfade() function.
You would start off with applying a blend filter to the element (with a duration of 600ms):
img.style.filter = 'blendTrans(duration=0.600)';Then, before making any change to the object, you would freeze its current state:
img.filters.blendTrans.apply();Finally you would change the image source and trigger the transition:
img.src = 'different-src.jpg';
img.filters.blendTrans.play();Effects Filters #
The filter category most people still remember from Internet Explorer 4+ is effects filters. In 1997 they already offered, although in a lower fidelity, what CSS Filters brought to the table when they first appeared in 2012 in Apple Safari 6.
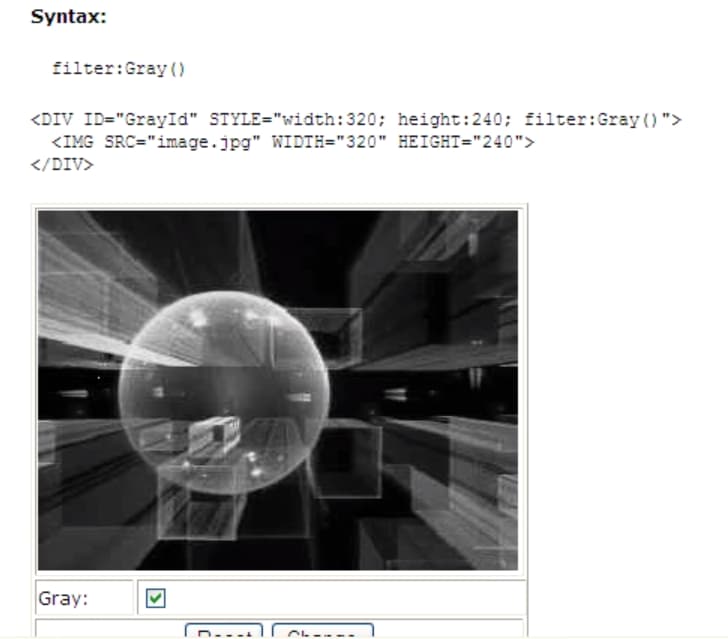
You could also use Internet Explorer's Matrix Filter to do things that would later be introduced by CSS Transforms:
transform: rotate(15deg);
filter: progid:DXImageTransform.Microsoft.Matrix(
M11=0.9659258262890683,
M12=-0.2588190451025207,
M21=0.2588190451025207,
M22=0.9659258262890683,
SizingMethod='auto expand');Or, you could use the Chroma Filter to key out certain color pixels of an element in order to create rounded corners or to apply masking.
Gradient Filter #
You always though Internet Explorer 10 was the first version to support gradients? Not entirely true, there was a CSS filter for that, too:
filter: progid:DXImageTransform.Microsoft.gradient(enabled='false',
startColorstr=#550000FF, endColorstr=#55FFFF00)Also note how Internet Explorer already supported 8-digit hex codes for RGBA colors, something that only officially appeared in CSS around 2016 as part of the CSS Color Module Level 4.
Custom Scrollbar Styling #
Internet Explorer first introduced custom scrollbar styling back in 1999 and it wasn't until 2013 that Safari came up with its own mechanic of styling them.
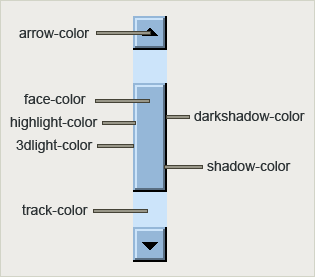
body {
scrollbar-base-color: #C0C0C0;
scrollbar-3dlight-color: #C0C0C0;
scrollbar-highlight-color: #C0C0C0;
scrollbar-track-color: #EBEBEB;
scrollbar-arrow-color: black;
scrollbar-shadow-color: #C0C0C0;
scrollbar-darkshadow-color: #C0C0C0;
}Box-Sizing #
Internet Explorer initially implemented the box model as if box-sizing: border-box was set by default. Even though many people found Microsoft's take a lot more logical and user friendly, the CSS WG ultimately chose another default where width was not referring to the outer width of a box but to width of the usable content space inside.
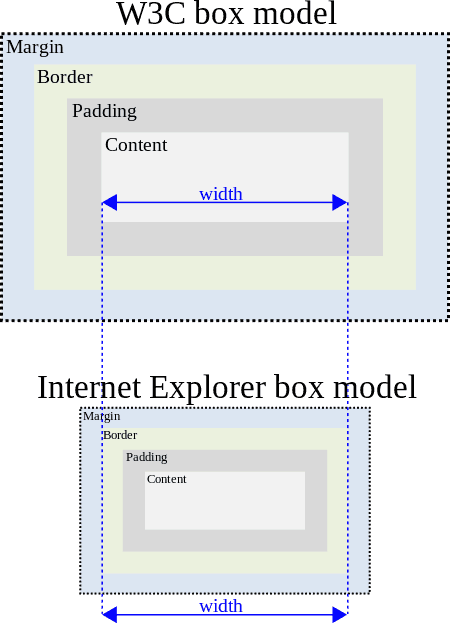
Logically, a box is measured from border to border. Take a physical box, any box. Put something in it that is distinctly smaller than the box. Ask anyone to measure the width of the box. He'll measure the distance between the sides of the box (the 'borders'). No one will think of measuring the content of the box. Web designers who create boxes for holding content care about the visible width of the box, about the distance from border to border. The borders, and not the content, are the visual cues for the user of the site. Nobody is interested in the width of the content.
It was only with IE 6 that Microsoft added an additional browser rendering mode, this time sticking to the standards. It was not active by default so not to mess old layouts up. You had to opt-in to it, which you would do by starting your HTML document with a doctype declaration (think of it as JavaScript's 'use strict';).
Nowadays everyone goes back to IE's model by starting off their CSS with resetting the box sizing:
html {
box-sizing: border-box;
}
*, *::before, *::after {
box-sizing: inherit;
}CSS Expressions #
Up until version 7, Internet Explorer had a great feature called "CSS Expressions", also known as "Dynamic Properties". In essence, they were JavaScript snippets wrapped in a CSS function and what the snippet evaluated to went into the CSS property's value. They could be considered as one precursor of CSS Houdini and CSS'es calc() function and other functions.
You could for example script your own min() and max() functions:
width: expression(Math.min(this.parentElement.clientWidth, 400) + 'px');The above code would set the width of the element to the width of the parent until it exceeds 400px. Then it would stop there, similarly to how max-width works. The this keyword would refer to the current element.
Since IE only supported pseudo-elements from version 8 on, you could use CSS Expressions to "polyfill" these, like so:
zoom: expression(
this.runtimeStyle.zoom = '1',
this.insertBefore(document.createElement('span'),(this.hasChildNodes()
? this.childNodes[0]
: null)).className='before',
this.appendChild(document.createElement('span')).className='after'
);The code above is assigned to a more or less irrelevant CSS property: zoom. The first thing it would do is to disable further executions of the expression by replacing it with a static value of 1. This stops it from creating more and more elements with every new evaluation run. Then it creates <span> elements which it injects at the beginning and end of its content area, with the CSS class names .before and .after. Since Internet Explorer 8 was the first version to support pseudo-elements but at the same time dropped support for CSS Expressions, the above code would do no damage in pseudo-element aware browsers.
The reason CSS Expressions were dropped so early from IE was that they quickly acquired themselves a bad image. And that was because with CSS Expressions you could quickly tank a website's rendering performance, bringing it to a crawl. The "problem" with CSS Expressions was that they executed after every single event that the browser registered, which also included resize, scroll and mousemove. Have a look at the following example:
background: expression('#'+Math.floor(Math.random()*16777216).toString(16));The above code would randomly calculate a HEX color which would then be assigned as background.You can see it in action in the following video (epilepsy warning because of flashing colors):
See how the background color updates every time one moves the mouse? This is indeed bad for performance, which is why leading figures in the web development scene soon started advising against using them or to replace them with real JavaScript. Back in the days, though, only a few were really versed at writing JavaScript, including me. Nowadays I would argue that it all depends on how you write your code and that you can equally create badly performing code in proper JavaScript. One solution to the problem is the one shown in the pseudo-element code, where the expression disables itself after the first run by assigning a static value to this.style or this.runtimeStyle (which is another proprietary Microsoft thing representing a style object with even higher precedence in the CSS cascade than inline styles). If the value was meant to stay dynamic, you could modify the code to only do costly calculations when it was supposed to:
<script>
window.calcWidth = '100%';
window.updateWidth = false;
window.onresize = function() {
window.updateWidth = true;
};
</script>
<style>
.element {
width: expression(
updateWidth ?
(
calcWidth = Math.min(this.parentElement.clientWidth, 400) + 'px',
updateWidth = false
) :
calcWidth
);
}
</style>But why not just use plain JavaScript? Well, it's true that you can do all of these things with pure JavaScript. One thing though, that I find super handy about expressions, is that they are easier to invoke on many different sorts of elements, as you can use CSS (selectors) to assign them to elements. And in the case of the pseudo-element polyfill expression it makes even more sense to have it in your CSS as that's also the place where you would create real pseudo-elements. So it depends.
Fonts #
Internet Explorer was the first browser to allow the use of custom fonts. The corresponding @font-face rule was part of CSS 2.0 but got pulled out of CSS 2.1 as browser support was too bad - mostly due to font foundries opposing the idea of putting fonts into the web, easy to pirate for everyone. Microsoft continued to support it and paired it with a new file format, which they developed together with the font foundry Monotype: the Embedded OpenType (EOT) format. EOT was meant to tackle these problems from two directions. On the one side, authoring tools, like Microsoft's Web Embedding Fonts Tool (WEFT), would only accept source fonts that were not marked with a no embedding flag. That way font foundries could disallow the use of them on the web. On the other side, during creation, you would specify a list of allowed URLs for the font to be used on and the browser would then check against it and only display the font if the current URL was indeed listed.
Microsoft and Monotype submitted EOT to be standardized to the W3C in 2008. But ultimately, the other browser makers of that time decided not to implement it, as it didn't use the (then) commonly supported GZIP algorithm for compression, but a proprietary algorithm called "MicroType Express" which they didn't want to implement on top. So instead they asked the W3C to develop yet another font embedding format, but based on GZIP, which in 2010 appeared as the WOFF format.
Rather than embed the URL of a document in the font, it relies on an HTTP feature (the origin header), which allows to give the domain part of a document's URL: less precise than a full URL, but still good enough for most font makers. In the end, however, WOFF still adopted parts of EOT's MicroType Express algorithm, and a new compression algorithm (Brotli), because it allowed better compression than gzip.
Fun fact: Did you know that when you chose to embed fonts into a Powerpoint 2007 or 2010 presentation, that Powerpoint would embed that font as an EOT file in the corresponding .pptx?
HTML Components: Attached Behaviors, Element Behaviors & Default Behaviors #
As early as 1998, Microsoft already suggested techniques that came close to what we celebrate today as CSS Houdini and Web Components: HTML Components:
The growth of HTML with scripting as an application platform has exploded recently. One limiting factor of this growth is that there is no way to formalize the services that an HTML application can provide, or to allow them to be reused as components in another HTML page or application. HTML Components address this shortcoming; an HTML Component (HTC for short) provides a mechanism for reusable encapsulation of a component implemented in HTML, stylesheets and script.
Componentization is a powerful paradigm that allows component users to build applications using 'building blocks' of functionality without having to implement those building blocks themselves, or necessarily understand how the building works in fine detail. This method makes building complex applications easier by breaking them down into more manageable chunks and allowing the building blocks to be reused in other applications. HTML Components brings this powerful development method to Web applications.
In fact, Microsoft's work was considered prior art in the early Web Component discussion.
The first browser to implement HTML Components was Internet Explorer 5 in 1999 and the last one was Internet Explorer 9 in 2010.
And there were three kinds of HTML Components: Attached Behaviors, Element Behaviors, and Default Behaviors.
Attached Behaviors #
Attached Behaviors worked similarly to a CSS Houdini Worklet in that you had a (.htc) file which would add new capabilities to any element it was attached to. The attaching itself was done via CSS:
img {
behavior: url(roll.htc);
}The .htc files consisted of special XML markup used to connect with the outside world, and a script block which would define how the element would behave. The attached DOM element was exposed to the script as the element global. The following Attached Behavior is tailored for image elements and would change their source every time the mouse would hover over them (hat tip for his deep dive and and credit for all of the following examples goes to Jasper St. Pierre):
<public:attach event="onmouseover" onevent="rollover()" />
<public:attach event="onmouseout" onevent="rollout()" />
<script>
var originalSrc = element.src;
function rollover() {
element.src = "rollover-" + originalSrc;
}
function rollout() {
element.src = originalSrc;
}
</script>Element Behaviors #
Element Behaviors went one step further by not only outsourcing behavior into a .htc file but also markup, thereby creating a custom element. This is pretty similar to Web Components' Custom Elements which also look trivial from the outside, from the "Light DOM", but hide a complex DOM structure inside in their Shadow DOM. Microsoft's version of Shadow DOM is called "Viewlink", into which you can opt-in, and like Shadow DOM it will protect the inner structure from any document styles bleeding in or from external scripts manipulating it.
Viewlink is a feature of element behaviors that enables you to write fully encapsulated Dynamic HTML (DHTML) behaviors and import them as robust custom elements in a Web page.
In order to use Element Behaviors it wasn't enough anymore to use CSS to tie an HTML element to a behavior. Instead you had to leverage the power of XML by creating a new namespace for your custom components:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html xmlns:custom>
<head>
<?import namespace="custom" implementation="RollImgComponent.htc">
</head>custom is a XML namespace name which you could freely chose. It could also be something else. The <?import> tag does what we previously used CSS for: referring to a .htc file holding the code for that component. In the .htc file, you then needed to add a few more parts:
- You needed to define the custom HTML tag under which to use the element:
<public:component tagname="rollimg"> - You had to define any HTML attributes this element allowed for, e.g.:
<public:property name="src" /> - And you needed to add the inner markup of your element similarly to today's
<template>element.
<public:component tagname="rollimg">
<public:attach event="onmouseover" onevent="rollover()" />
<public:attach event="onmouseout" onevent="rollout()" />
<public:property name="src" />
</public:component>
<img id="image" />
<script>
// IE's document.getElementByID
var img = document.all['image'];
img.src = element.src;
img.id = undefined;
element.appendChild(img);
function rollover() {
img.src = "rollover-" + element.src;
}
function rollout() {
img.src = element.src;
}
</script>Note that within the .htc file you had your own scoped document object to traverse.
Now you were ready to go and use your custom element in your HTML markup like so:
<custom:rollimg src="logo.png">Custom elements like these were synchronously parsed and created. After the creation of the above example component the page's DOM would look like this:
<custom:rollimg src="logo.png">
<img src="logo.png" />
</custom:rollimg>As you can see, these img elements became visible and could therefore be targeted from with the HTML document via DOM traversal or CSS. Which may not have been what you wanted. To fix that, you needed to activate Internet Explorer's version of Shadow DOM called "viewLink", like so:
<public:component tagname="rollimg">
<public:attach event="onmouseover" onevent="rollover()" />
<public:attach event="onmouseout" onevent="rollout()" />
<public:property name="src" />
</public:component>
<img id="image" />
<script>
// Activates IE's Shadow DOM
defaults.viewLink = document;
// IE's document.getElementByID
var img = document.all['image'];
img.src = element.src;
function rollover() {
img.src = "rollover-" + element.src;
}
function rollout() {
img.src = element.src;
}
</script>Default Behaviors #
Default Behaviors are the third variant of HTML Components. They are basically standard libraries built into the browser that you could tap into via CSS or XML extension and that unlocked a completely new set of functionality.
Triggering a Download #
One of them was behavior:url(#default#download).
Nowadays when you want to trigger a download just from within the front-end, what you would do is make use of a link with a download attribute and execute .click() on it. Well, back in the old days it went like this:
<!--
the following element needs to be created once in the document.
It then exposes new utility methods you can use, like .startDownload()
-->
<span id="download" style="behavior:url(#default#download)"></span>
<button onclick="download.startDownload('menu.pdf')">Download</button>Persisting Data #
Another super useful Default Behavior was behavior: url(#default#userData). It solves the same problems as localStorage does, just in a completely different manner. The following illustrates how to save and restore the values of input elements in old IE:
<style>
#store {
behavior: url(#default#userData);
}
</style>
<script>
function save(){
store.setAttribute('username', username.value);
store.setAttribute('email', email.value);
store.save('exampleStore');
}
function restore(){
store.load('exampleStore');
username.value = store.getAttribute('username');
email.value = store.getAttribute('email');
}
</script>
<span id="store"></span>
<input id="username">
<input id="email">
<button onclick="restore()">restore values</button>
<button onclick="save()">save values</button>There is even localStorage polyfills for IE that use this technique.
Client Capabilities #
Another Default Behavior is the Client Capabilities Behavior. As the name already hints at, it allows you to find out more about the client. The most interesting piece of information is the one about the user's connection type, similar to today's navigator.offline or the Network Information API:
<span id="clientcapabilities"
style="behavior:url(#default#clientCaps)">
</span>
<script>
// Either "modem" or "lan" or "offline"
var connectionType = clientcapabilities.connectionType;
</script>Animating via Timed Interactive Multimedia Extensions #
You think Internet Explorer could not animate stuff? Not entirely true. Because, back in the days there was already SMIL, the Synchronized Multimedia Integration Language. SMIL is a markup language to describe multimedia presentations, defining markup for timing, layout, animations, visual transitions, and media embedding. While Microsoft was heavily involved in the creation of this new W3C standard, they ultimately decided against implementing it in Internet Explorer. What they did, though, was to derive from it a dialect that would integrate with HTML and submitted that to W3C, too: HTML+TIME, the Timed Interactive Multimedia Extensions. The W3C later reworked it into something that became part of SMIL 2.0 and that was called XHTML+TIME. Internet Explorer 5 was the first browser to support it in 1999 in version 1.0. Internet Explorer 5.5 one year later supported HTML+TIME version 2.0, the implementation of which was closer to W3C's XHTML+TIME draft. Microsoft still held on to the old name without a leading X, though.
This feature was also encapsulated in a Default Behavior which you had to activate first, either by CSS or by extending the (XML) namespace. Afterwards, what you could do with it was e.g. to show and hide elements over the course of ten seconds, five times in a row:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<style>
.time {
behavior: url(#default#time2);
}
</style>
</head>
<body>
<div class="time" repeatcount="5" dur="10" timecontainer="par">
<p class="time" begin="0" dur="4">First line of text.</p>
<p class="time" begin="2" dur="4">Second line of text.</p>
<p class="time" begin="4" dur="4">Third line of text.</p>
<p class="time" begin="6" dur="4">Fourth line of text.</p>
</div>
</body>
</html>Or, switching to the XML namespace variant, you could animate HTML attributes like the background color of the body:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html xmlns:t="urn:schemas-microsoft-com:time">
<head>
<?import namespace="t" implementation="#default#time2">
</head>
<body id="body">
<t:animateColor targetElement="body"
attributeName="backgroundColor"
from="black" to="white"
begin="0" dur="3" fill="hold"/>
</body>
</html>Or you could embed a video or audio in HTML, similarly to how you use <video> or <audio> nowadays, and even have accessible HTML controls:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html xmlns:t ="urn:schemas-microsoft-com:time">
<head>
<?import namespace="t" implementation="#default#time2">
</head>
<body>
<t:video id="video" src="video.mpeg" type="video/mpeg"/>
<div class="controls">
<button type="button" onclick="video.resumeElement()">play</button>
<button type="button" onclick="video.pauseElement()">pause</button>
<button type="button" onclick="video.speed = 1">1x</button>
<button type="button" onclick="video.speed = 4">4x</button>
</div>
</body>
</html>All formats were supported for which the underlying Windows operating system found an appropriate decoder. By default those were for example MPEG-1 and AVI encoded with Microsoft Video-1 codec.
You could even combine the Microsoft specific format with HTML5:
<video id="html5video" autoplay muted>
<source src="video.mp4" type="video/mp4"/>
<t:video id="video" src="video.mpeg" type="video/mpeg"/>
</video>
<div class="controls">
<button type="button"
onclick="html5video.play ? html5video.play() : video.resumeElement()">play</button>
<button type="button"
onclick="html5video.pause ? html5video.pause() : video.pauseElement()">pause</button>
<button type="button"
onclick="html5video.playbackRate = video.speed = 1">1x</button>
<button type="button"
onclick="html5video.playbackRate = video.speed = 4">4x</button>
</div>You find the demo here. You'll need a (virtual) machine with IE 5.5-8 to experience the IE implementation which you see in the above video.
Vector Markup Language #
Microsoft were also the first to support a vector graphics format in a browser in 1999: the Vector Markup Language, in short VML. VML was developed by Autodesk, Hewlett-Packard, Macromedia, Microsoft, and Vision and submitted to the W3C in 1998. Unfortunately, around that same time, the W3C also received a competing submission called Precision Graphics Markup Language (PGML), developed by Adobe Systems and Sun Microsystems. So W3C merged both proposals and created the Scalable Vector Graphics format (SVG) in 2001. The first browser to support SVG was Konqueror 3.2 in 2004.
To be honest, there isn't much to complain about VML, other than that it could only be used embedded into an HTML file, not externally referenced. Here is how you would create an ellipse both in SVG as well as in VML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>SVG Ellipse</title>
</head>
<body>
<svg>
<ellipse cx="200"
cy="80"
rx="100"
ry="50"
fill="yellow"
stroke="purple"
stroke-width="2" />
</svg>
</body>
</html><!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN">
<html xmlns:v="urn:schemas-microsoft-com:vml" lang="en">
<head>
<title>VML Ellipse</title>
<style>v\:* {behavior:url(#default#VML);}</style>
</head>
<body>
<v:oval
style="position: absolute; width: 200; height: 100; left: 100; top: 30;"
fillcolor="yellow"
strokecolor="purple"
strokeweight="2">
</v:oval>
</body>
</html>Both dialects look similar and seem equally unfamiliar to us web developers.
Data Binding #
Back since Internet Explorer 4.0 in 1997 you could embed data sources into your document. This could be done by referencing an external CSV file via <object> element:
<object id="data" classid="clsid:333C7BC4-460F-11D0-BC04-0080C7055A83">
<param name="DataURL" value="data.csv">
</object>Instead of a CSV file you could also establish a connection to your database server (not suggested in writing mode :):
<object id="data" classid="clsid:BD96C556-65A3-11D0-983A-00C04FC29E33">
<param name="Server" value="http://server">
<param name="Connect" value="dsn=database;uid=guest;pwd=">
<param name="SQL" value="select name from people">
</object>(Note how the classid attribute changes depending on the source of data?)
And finally you could also reference an external XML file via <xml> tag…
<xml src="http://localhost/xmlFile.xml"></xml>…or use embedded inline XML in HTML as your data source:
<body>
<xml id="data">
<?xml version="1.0" encoding="UTF-8" ?>
<records>
<record>
<name>Willa Galloway</name>
<email>tortor@dictum.com</email>
<phone>098-122-8540</phone>
<city>Tenali</city>
</record>
<record>
...
</record>
...
</records>
</xml>
</body>That inlined XML was called "XML Data Islands" and it worked similarly to how browsers nowadays handle SVG embedded in HTML or HTML embedded into an SVG <foreignObject> by switching to another parser on the fly.
An XML data island is an XML document residing within an HTML page. This avoids having to write code (i.e. a script) just to load the XML document, or having to load it through a tag. Client side scripts can directly access these XML data islands. These XML data islands can be bound to HTML elements also.
Now that you had the data in your page you could use Internet Explorer's data binding to e.g. edit it:
<input type="text" datasrc="#data" datafld="name">2-way Data Binding #
Not only could you bind data to an input, but also to arbitrary elements. And you could create a two-way data flow, just with declarative markup:
<xml id="data">
<record>
<name></name>
</record>
</xml>
<h1>Hello, <span datasrc="#data" datafld="name"></span>!</h1>
<label>Your name: <input datasrc="#data"
datafld="name"
onkeyup="this.blur();this.focus()">
</label>The only reason there is onkeyup="this.blur();this.focus()" is to trigger data flow after each key press, as otherwise the other connected elements would only receive the updated value after the user left the input.
Data Grids #
Internet Explorer also shipped with a native data grid implementation that you hooked up to the above data sources and which is built on top of the <table> element. This was called Tabular Data Control. You would use the HTML attributes datafld to map data fields to table columns, dataformatas to enable or disable HTML entity encoding of the contained data, and the datapagesize attribute to denote how many entries a page of the grid should show at once. And then there were the methods previousPage, nextPage, firstPage, lastPage to easily navigate through the pages.
<table id="datagrid"
datasrc="#people"
datapagesize="10">
<thead>
<tr>
<th>Name</th>
<th>Email</th>
<th>Phone</th>
<th>City</th>
</tr>
</thead>
<tbody>
<tr>
<td><span datafld="name"></span></td>
<td><span datafld="email"></span></td>
<td><span datafld="phone"></span></td>
<td><span datafld="city"></span></td>
</tr>
</tbody>
</table>
<button onclick="datagrid.previousPage()">< previous</button>
<button onclick="datagrid.nextPage()">next ></button>Property Change Event #
Internet Explorer featured an interesting propertychange event, which you could attach to DOM elements and which would trigger each time one of its properties would be changed programmatically. This could have happened via setAttribute() or via object property access. This allowed to create observed/instrumented objects for similar use cases you could use ES Proxies nowadays. All you needed was a dummy DOM element with propertychange event applied:
<div id="store"></div>
<script>
function handler() {
// A magic 'event' variable is passed into
// the event handler function. When coming
// from the 'propertychange' event, it comes
// with a 'propertyName' property.
if (event.propertyName === 'onpropertychange') {
// Don't execute right at the beginning on itself
return;
}
alert(
event.propertyName +
'\'s value was changed/set to "' +
store[event.propertyName] +
'"'
);
}
store.onpropertychange = handler;
store.test = true;
store.test = false;
store.literal = {};
store.literal = {
key: 'value2'
};
</script>Resize Events for DOM Elements #
Internet Explorer had plenty of unique events, but the most interesting one is the element based resize event, available up until IE 9.
The onresize event fires for block and inline objects with layout, even if document or CSS (cascading style sheets) property values are changed.
This event is basically in relation to Resize Observer what mutation events are to the Mutation Observer. With the only difference to the usual events in that it triggered asynchronously, similarly to an observer.
element.onresize = function(e) {
/* React to the element's size change */
}JavaScript Preloading #
One interesting implementation of Internet Explorer was how it would load and execute JavaScript sources added via script:
var script = document.createElement('script');
var head = document.getElementsByTagName('head')[0];
script.src = '...';
head.appendChild(script);Other browsers would fetch and execute such a script the moment it was appended to the DOM. Internet Explorer had a more nuanced approach: it splitted both steps up. Fetching already happened as soon as the .src property was assigned whereas execution only happened once the script was appended to the DOM. That way you could easily preload scripts without blocking the main thread. Something developers could only implement in a more complicated fashion in other browsers, at least until we got Resource Hints.
Internet Explorer was also the first browser to introduce the defer attribute for scripts.
Finding the currently executing script #
At some point, the HTML5 standard introduced document.currentScript which pointed to the <script> element which was currently being executed. Why would you need this? For example to read out extra configuration like this one in the data-main attribute:
<script src="scripts/require.js" data-main="js/main"></script>Somewhere inside scripts/require.js there would be this line:
var main = document.currentScript.getAttribute('data-main');Sadly, this only got implemented in Edge 12. What only a few people knew was that Internet Explorer had another mechanism in place which not only offered the same result, but that was also more in line with how a document would communicate if it was still loading or if it was fully interactive: scripts had a .readyState property.
function currentScript() {
var scripts = document.getElementsByTagName('script');
for (; i < scripts.length; i++) {
// If ready state is interactive, return the script tag
if (scripts[i].readyState === 'interactive') {
return scripts[i];
}
}
return null;
}The .readyState property was dropped in Internet Explorer 11 which made this version the only one supporting neither .currentScript nor .readyState (luckily, a genius named Adam Miller found another way to polyfill it).
So what led to IE's downfall? #
Looking at the above list, I would say that Microsoft was lightyears ahead of everyone else in regards to providing tools and solutions for architecting complex and delightful websites. Some syntax may look unfamiliar to us, but this is just because we are not used to it. Back in the days, XML was all the rage. And remember how you felt when you opened an SVG for the first time? Or when you saw ES6'es arrow notation? Or BEM? JSX? You probably had the same feelings.
One part of why Microsoft's ideas didn't really catch on was that we developers just didn't get it. Most of us were amateurs and had no computer degree. Instead we were so busy learning about semantic markup and CSS that we totally missed the rest. And finally, I think too few people back then were fluent enough in JavaScript, let alone in architecting complex applications with JavaScript to appreciate things like HTML Components, Data Bindings or Default Behaviors. Not to speak of those weird XML sprinkles and VML.
The other reason could have been a lack of platforms to spread knowledge to the masses. The internet was still in its infancy, so there was no MDN, no Smashing Magazine, no Codepen, no Hackernoon, no Dev.to and almost no personal blogs with articles on these things. Except Webmonkey. There were also no conferences yet, where Microsoft devrel people could have spoken. And there was also no broadband and therefore no conference talks you could have watched on video. All there was, was mailing lists like "A List Apart" and IRC to get in contact with others, which was basically Slack, but with a lot less polish.
The final nail in the coffin was that after the release of Internet Explorer 6, Microsoft decided to tightly couple new Internet Explorer releases to Windows releases. So they dismantled the Internet Explorer team and integrated it into the Windows product team. Sadly, the Windows version in the making, Windows XP's successor with codename "Longhorn" (later Windows Vista), got massively delayed as development was so unfocused and chaotic that they even needed to reset it. This also delayed a new Internet Explorer release and left the web in a vacuum, with no one fixing bugs and improving existing technology. When Microsoft woke up five years later, it was already too late. W3C had developed new standards and the remaining other browser makers not only implemented them but also founded the WHATWG which brought even more innovations to the table. Microsoft lost its technical leadership, lost its market share, and never recovered from that period.

Update: don't miss the interesting discussion happening over at Hacker News.
The cover photo of this post is shot from within the ruins of the Monument House of the Bulgarian Communist Party, built on Buzludzha Peak in central Bulgaria by Natalya Letunova on Unsplash
Webmentions

-

-
-
-
When I was a child, I was always fascinated by stories about ancient civilizations. I devoured books about Atlantis, or the story of Heinrich Schliemann’s discovery of Troy, stories about the Greek, the Romans, the Inca Empire, or Ancient Egypt. And I was alw… Read More
-
-
-
Great post. Lots of quirky peculiarities that I really appreciated! But the Trident Zombie may still rise from the death with Edge's IE-Mode... docs.microsoft.com/en-us/deployed… :-)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
Starting now, Microsoft will roll out their new Chromium-based Edge browser to their millions of Windows 10 users. And this will also mark the end of an era. The era of the Trident-Engine.
But hadn’t the Trident era already ended when Edge appeared? Not really.
This is a very deep look at the Trident engine. Goodness.
-
-
-
-
-
IE6 vs. the Acid2 test. It was only until IE8 that it passed Acid2.
When “Edgium” got released about a month ago, Schepp also wrote an extensive piece to commemorate the Trident rendering engine.
Back in the days, Microsoft was single-handedly pushing the web forward, with around 1.000(!) people working on Internet Explorer and with a 100 million dollar budget to burn per year, with almost no-one left to compete. This was massive!
As I’ve been tinkering with the web for almost 25 years by now, I remember many of the stuff mentioned. IE/Trident gave us many great things, and sometimes was ahead of its time, lest we forget.
-
-
-
A history of the render engine behind Internet Explorer, and the various ‘innovations’ that Microsoft introduced back in the day, some more successful than others.
-
@matthiasott @matuzo ????????????
-
@matthiasott @matuzo This time I feel more prepared, though! ????️
-
 Christian Schaefer
Christian Schaefer
 Martin Donath
Martin Donath
 Marc Görtz
Marc Görtz
 Frederik Braun �
Frederik Braun �
 Hagbard Celine
Hagbard Celine
 Stoyan Stefanov
Stoyan Stefanov
 Catalin Rosu
Catalin Rosu
 Matt Greer
Matt Greer
 Marc Hinse
Marc Hinse
 😏
😏
 Frederic'); DROP TABLE tweets;--
Frederic'); DROP TABLE tweets;--
 dirk döring
dirk döring
 Nick Ribal @ 🇹🇭
Nick Ribal @ 🇹🇭
 Philippe Majerus
Philippe Majerus
 Ethan Marcotte
Ethan Marcotte
 Valentin Pletzer
Valentin Pletzer
 Eva (kein) Bock 🐞
Eva (kein) Bock 🐞
 TheGuvnor
TheGuvnor
 Christian "Schepp" Schaefer
Christian "Schepp" Schaefer
 Matthias Ott
Matthias Ott